


【筆記】Presto實作 (一)前言

最近有個特殊的需求,需要將『分散的異質資料』做一個查詢。
白話一點就是「不同伺服器的不同類型資料』
而實作上則是需要使用到「presto」
至於Presto是什麼,最簡單的解釋大概是下圖

泛指任何端點,可以透過通用的query 去查詢不同類型與不同伺服器的資料
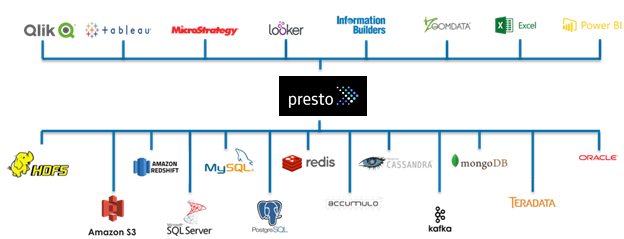
而 Presto能夠接收的儲存來源類型也非常的多元
(一) 官網
目前的Presto,共有二個官網:
分為prestodb ,prestosql
老實說一開始,我還真分不清哪一個才是真正的「presto」。
二個都有自己的獨立官網,自己獨立的git倉庫,自己獨立的社群。
後來爬了一些文章才理解
https://prestodb.io/,算是比較"正統"的官網。
其實從專案的commit可以看出端倪。
prestosql 從0.215版後,「分支」跳號出來的。
0.215後,它的版本號獨立為300以後。
二個版本正式產生出了分歧點。
在追查相關新聞後。更確定了理論。
prestodb 是原始系統的主幹,主要由原團隊維護。
prestosql 是被定義為「社區管理版本」,也就開源社群們的各種貢獻分享。
因為資料庫的stroge是很多種類型的,可以從社群版本看到
很多新的connection都是原始主幹沒有提供的。
簡單來說,就是prestodb 是FB團隊衍生出的東西,是原始的主幹
之後成立基金會,為了讓開源更好,整合了社區,又創建了prestosql
二個都算是官方的東西。只是在定義上不太一樣。
系統上其實也差沒多少,(二個都架設運行過)
差別只差在connection的插件。
(二) 架構簡介

「presto」的架構如上,其實也不複雜。
在presto這個架構裡,有主要重點的3個角色。
(1)discovery
discovery算是總機的概念,也就是一個索引伺服器。
在連線的時候,會去查找這個索引清單,從而知道所有work跟coordinator的位置。
正常來說disocvery 默認配置是跟coordinator是一起的。
簡單來說就是可以分散式的系統,彼此都能知道對方的存在,以及能夠互相溝通。
實作上則是要配置一個json文件,把disocver的uri指向這個文件即可。
(2)coordinator
coordinator算是一個PM,假設用戶發來一條query作為查詢。
這個PM就會負責將查詢的工作,分配給下面的worker去進行。
並且監督所有worker的任務都完成,再將查詢結果(respon)回報給用戶。
(3)worker
worker就是最底下執行單一任務的人,也就是面對不同的儲存體。
譬如有的worker面對的是mysql資料庫,有的worker面對的是csv 或是 s3。
但是最後都會把查詢結果,轉換成相同的資料流回報給上層的PM。
(三) 前言總結
在實務上,比較好的方式,當然是coordinator + discover,worker獨立分開。
由coordinator 作為一個query接收以及派發的代表,本身又有dicover server功能。
而不同的storge則靠worker去作為一個管理。
以架設方面,其實程式都是同一包。
presto在程式的設定檔上,可以去設定角色。
決定要讓這個程式,成為coordinator ,或是worker,
甚至二者可以合而為一,coordinator 身兼worker。
實作架設的部分,就之後再進行介紹。

張貼留言